Jobs Service Architecture¶
Table of Contents
Design Guidelines¶
The focus of the Jobs service redesign is to improve reliability, scalability, performance and serviceability. To achieve these goals, the following design guidelines are observed:
- Efficient database usage
- Database polling is prohibited
- Database transactions boundaries are clearly defined
- Database reads and writes are optimized for each application task
- Database calls are logged and monitored
- Queue management system
- A message broker manages asynchronous communication
- The broker provides quality of service guarantees (durability, redelivery on client failure, etc.)
- Explicit Job state machine
- Only valid state transitions are allowed
- One designated thread is responsible for all state changes for a job
- Separation of front and back ends
- HTTP data types and processing are limited to the new Aloe web application
- Backend job processing is performed by Java workers running in their own JVMs
- Horizontal scaling is achieved by adding more workers
- Recovery subsystem
- A separate process manages transient errors
- Aggregation of all jobs blocked on same error condition
- Support for customizable recovery policies
- Efficient thread management
- Dedicated threads manage asynchronous messaging to jobs and workers
- Thottled thread restarting during recovery
- Actionable error messages and log records
- Capture enough data for root cause analysis
- Cryptographic validation of requests
- JWT signatures are checked
- Software engineering best practices
- Technology choices that simplify design, code, operations and deployment
- Example: removal of Hibernate
- Example: use of JAXRS reference implementation
- Example: standardized treatment of configuration files, environment variables and command line parameters
3 Tier Architecture¶
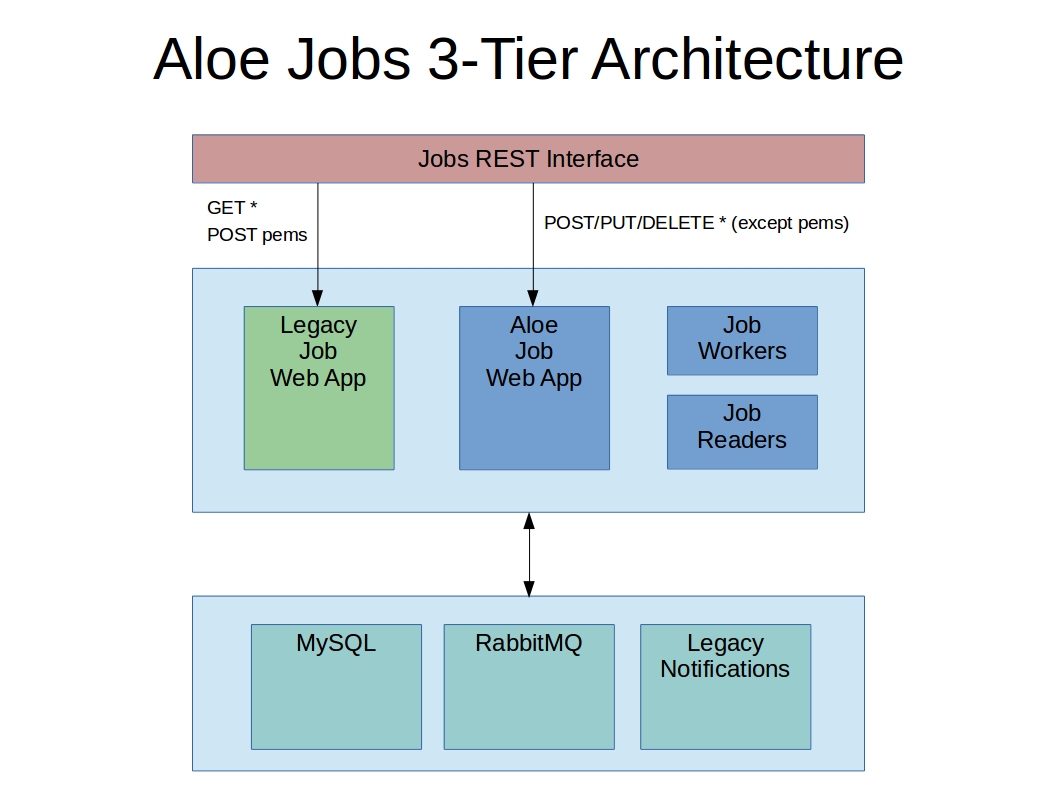
The Jobs service implements a 3-tiered application with the user interface layer defined by a REST API, the application layer comprised of Java web applications and daemons, and the persistence layer comprised of a MySQL database, a RabbitMQ queue management system and the existing Tapis Notifications service.
REST API Layer¶
The Jobs REST Interface provides the interface through which web portals and other applications can communicate with the Jobs service. As much as possible, the API maintains the legacy Tapis syntax and semantics, see Job Service Changes for details.
Application Layer¶
The application layer implements job REST endpoints using two web applications. The Legacy Job Web Application supports all HTTP GET requests and all permission requests. The Legacy web application is a stripped down version of the Tapis Jobs front end ported to work with an updated MySQL schema; it does not interact with the queue management system nor does it benefit from a redesign. The rationale for porting part of the existing application was purely economic: We were able to significantly reduce development and test effort by reusing existing code for read-only and permission related requests. By not rewriting the REST APIs that do not directly interact with running jobs we could focus on improving job execution (see Design Guidelines).
The new Aloe Job Web Application handles all POST, PUT and DELETE requests except those concerned with permissions. The main function of this new web application is to accept requests for job execution and cancellation. In addition, requests to resubmit jobs and requests to change the visibility of jobs are also supported. This web application interacts with both the MySQL database and the RabbitMQ messaging system.
Each tenant is configured with at least one Job Worker application, which is a standalone Java daemon running in its own JVM. Each job worker reads job submission requests from a single queue and executes those requests. Workers can process multiple job requests at a time. For scalability, multiple workers can service the same queue and tenants can define multiple submission queues for even greater flexibility.
Job Readers are standalone Java daemons that run in their own JVM and perform specialized tasks related to job execution. These programs are called readers because they receive their input by reading a specific queue or topic. The three readers currently implemented are the recovery reader, alternate reader and dead letter reader. See Workers and Readers below for details.
Persistence Layer¶
The web applications, workers, readers and numerous administrative utility programs access the MySQL database. For performance, reliability and design simplicity, all database access from the Jobs service (other than from the legacy web application) is via direct JDBC driver calls. The database schema contains six new tables, modifications to several existing tables and the removal of the Tapis jobs table. The contents of the Tapis jobs table are migrated to the new aloe_jobs table to maintain historical continuity. A single database instance continues to support all tenants in the system.
The RabbitMQ queue management system was introduced in Aloe to provide reliable, non-polling communication between application layer components. Most exchanges, queues, topics and messages are specified as durable so that they can be recovered in the event of an application or RabbitMQ failure. Unroutable messages are captured and logged. Undeliverable messages (i.e., dead letters) are also logged.
The Legacy Notifications service continues to support persistent, application-level event notifications. The new Jobs service calls the Tapis Notification service as it executes jobs, by and large preserving existing Tapis behavior from the client’s point of view (see Job Service Changes for details).
Workers and Readers¶
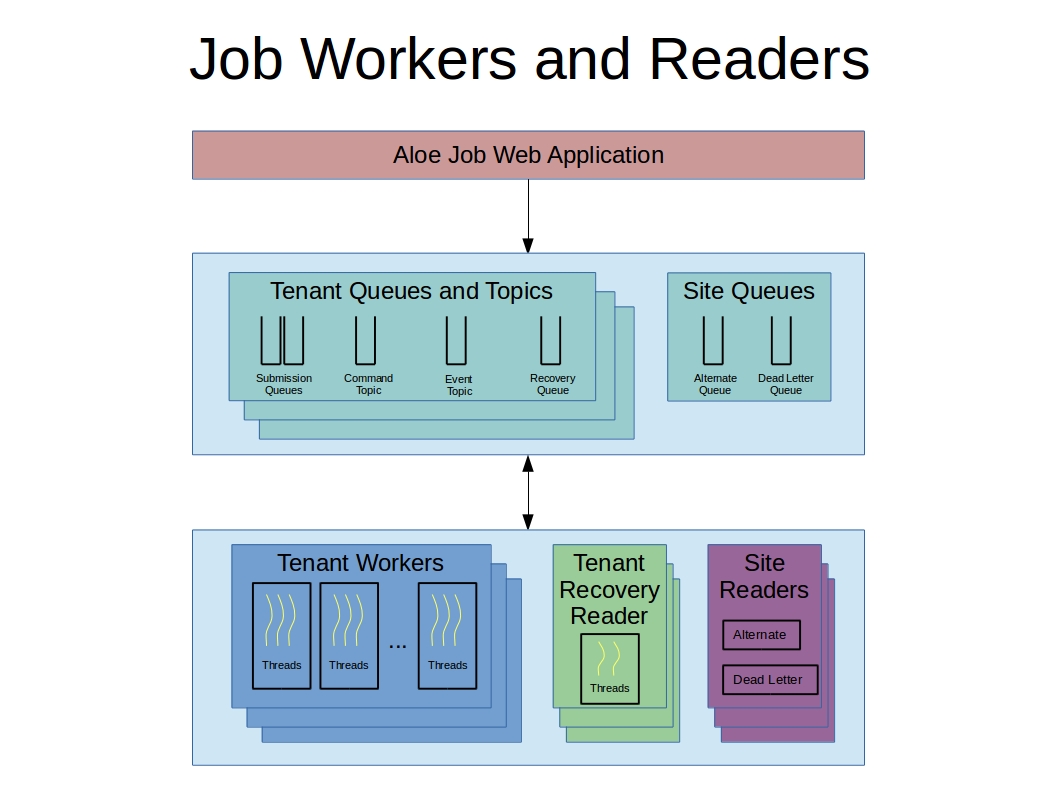
The application layer worker and reader programs are queue driven Java programs running in separate JVMs. Some of these programs service a single tenant while others service all tenants. The following sections describe each of these programs, their queues and topics, and the messages they process.
Tenant Workers¶
Tenant worker processes execute and manage the lifecycles of jobs on a per tenant basis. Every job starts out as a REST request to the Aloe web application, which then creates a submission message and places it on a tenant-specific submission queue. Here are the basic facts about how workers and their queues are configured:
- Each tenant has a default submission queue.
- A tenant can have zero or more other submission queues.
- Submission queues are not shared between tenants.
- Each worker process is assigned to one submission queue.
- A submission queue can have any number of workers assigned to it.
- A worker can process 1 to N submission messages at a time, where N is the number of threads configured in the worker.
Scalability¶
Job processing scales by (1) increasing the number of threads in a worker, (2) increasing the number of workers servicing a queue, or (3) by increasing the number of queues. These techniques can be used separately or in conjunction.
Increasing the number of threads in a worker increases the number of read operations blocked on a queue. RabbitMQ implements round robin scheduling to distribute message delivery evenly between worker threads. Since each worker is a Java program running in its own JVM, hundreds of threads can be configured per worker, limited in practice by the resources available on the host. Up to a point, this type of vertical scaling increases the amount of concurrent work performed without employing more servers.
Increasing the number of workers servicing a queue allows new server resources to be employed in a runtime environment. Starting a new worker inserts that worker’s threads into RabbitMQ’s round robin scheduling process. Since new workers can run on a existing server or on a newly added server, this is one way to scale horizontally.
Finally, increasing the number of submission queues defined in a tenant can also increase total throughput. Each queue comes at least one new worker, so job execution requests are split among more workers as we add queues. We implement a message routing algorithm based on a queue prioritization scheme and the attributes of job requests. The algorithm works by defining a guard or filter on each queue. These filters are Boolean expressions that reference attributes of a job request. Request attributes include the request originator, the application name, the job’s execution system, the time of day, the number of nodes required, etc. In addition, queues are given a unique priority within a tenant. When a job request is received the queue selection algorithm evaluates each queue’s filter in priority order. The first filter satisfied determines the queue selected for the job request. If no filter is satisfied, the default submission queue is selected.
This message routing algorithm allows requests to be segregated by workload characteristics. For instance, a tenant may define a queue for long running jobs to reduce the time to solution for short duration jobs. A queue may be defined for a specific power user so that their jobs are less affected by fluctuations in system load.
Asynchronous Communication¶
The first thing a job worker thread does when it reads in a job submission message is to spawn a job-specific command thread to handle asynchronous communication to that job. The command thread creates a temporary job-specific command topic and waits for asynchronous messages to be sent to the job. The most common message sent to a job is a cancellation message, usually originating from a REST call sent by the user that originally submitted the job. The command thread delivers messages through shared memory to its parent worker thread, which then takes action on the job it’s processing. To cover cases when jobs are in recovery and not assigned a worker, asynchronous messages destine for jobs are also sent to the recovery queue so they can be acted upon by Tenant Recovery Readers.
In addition to the command topic, the Jobs service designates an events topic for each tenant. The idea is that different system components can write well-defined events to the topic and interested parties can subscribe to the topic to receive some subset of those events. Eventually, a REST API will be developed to allow external subscriptions to the events topic. The events topic is not used in the initial Jobs service release.
Reliability¶
When a job worker thread reads a submission message from its assigned queue, it takes responsibility for seeing that job through until it terminates or becomes blocked. After spawning a command thread as described above, job processing begins by creating a job record in the MySQL database with PENDING status. At this point, the job is externally visible and can be queried or cancelled. The worker thread then begins validating the job configuration; locating input files and executables; contacting the execution, storage and archiving systems; staging the inputs and the executable package; monitoring the job as it executes on a remote system; cleaning up temporary files after remote execution completes; archiving the job output and logs; and, finally, putting the job into a terminal state.
A number of events can occur during job processing to delay or stop progress before the job completes. First and foremost, the job worker thread, the worker process, or the host running the worker could catastrophically fail. Such a failure could happen at any point during job processing and the requirement is that job execution should pick up where it left off as soon as possible.
This requirement to not lose jobs is addressed in two ways. First, job state is recorded in the database so that any worker restarting the job will know where to begin. The goal here is to minimize the amount of duplicate work performed during restarts. Second, and most important, is that the job’s submission message still resides in its submission queue during job processing. If the worker thread that read the message dies, RabbitMQ will automatically push the message to the next worker thread waiting on the queue. The queue broker guarantees the liveness of a job submission message until is it explicitly acknowledged by the worker responsible for it. Workers only acknowledge their messages when job processing terminates or becomes blocked.
Another error mode is the failure of RabbitMQ itself. This is a systemic failure comparable to the loss of the MySQL database. The Jobs service’s queues, topics, exchanges and messages are defined to be durable so that they can be recovered after a broker failure.
A discussion of the many ways a complex distributed system can fail and the effect those failures can have on running jobs is beyond this scope of this discussion. In scope, however, is how the system behaves when transient errors occur. The goal is to build into the Jobs service enough resilience to recover from temporary failures, which is where recovery readers come in.
Tenant Recovery Readers¶
Each tenant runs one tenant recovery reader daemon that reads messages from the tenant’s exclusive recovery queue. Recovery readers manage jobs while they are blocked due to some transient error condition. The temporary error conditions currently recognized by the recovery subsystem are:
- Unavailability of applications
- Unavailability of execution or storage systems
- Job quota violations
- Remote system connection failures
When any of the above conditions are detected during job execution, the worker processing the job will put the job into recovery by (1) setting the job’s status to BLOCKED, (2) placing a recovery message on the tenant’s recovery queue, and (3) removing the job from its submission queue. When a job is put into recovery responsibility transfers from the worker to the recovery subsystem. Special care is taken to ensure that a job appears on one and only one queue at a time. Support for additional error detection and recovery is expected to be added on an ongoing basis.
The recovery message contains information collected at the failure site and higher up in the executing job’s call stack. This information characterizes the error condition and specifies how the job can be restarted. Specifically, the recovery message specifies the policies and testers used to recover the job. Policies determine when the next error condition check should be made; testers implement the code that actually makes the check. New policies and testers can be easily plugged into the system, though at present they have to ship with the system.
The recovery reader is a multithreaded Java program that processes the tenant’s recovery queue. Internally, recovery messages are organized into lists based on their error condition—jobs blocked by the same condition are put in the same list. Recovery jobs are ordered by next check time and the recovery reader waits until that time to test a blocking condition. Recovery information is kept in the MySQL database for resilience against reader failures.
When a test indicates that a blocking condition has cleared, all jobs blocked by that condition are resubmitted for execution. Resubmission entails (1) setting the job status to the value specified in the original recovery message, (2) creating a job submission message and placing it on the job’s original submission queue, and (3) removing the job from the recovery subsystem and its persistent store. The job is immediately failed if it cannot be resubmitted. Resubmission transfers responsibility for the job back to the tenant workers. Care is again taken to ensure that a job cannot be both in recovery and executing.
Recovery readers also handle asynchronous requests initiated by users, such as requests to cancel a job in recovery. These requests appear as messages on the recovery queue.
Site Alternate Readers¶
The alternate reader daemon reads messages from the site-wide alternate queue shared by all tenants. The Jobs service provides a fail-safe destination for unroutable messages by specifying the alternate queue when defining RabbitMQ exchanges. Currently, the reader logs the messages it reads and, possibly, sends an email to a designated support account. See RabbitMQ Alternate Exchanges for more information.
Site Dead Letter Readers¶
The dead letter reader daemon reads messages from the site-wide dead letter queue shared by all tenants. The Jobs service provides a collection point for discarded dead letters by specifying the dead letters queue when defining RabbitMQ exchanges. Dead letters are messages that are rejected by the application without requeuing, messages whose time-to-live expires, or messages pushed to a full queue. The Jobs service does not currently set message time-to-live values nor does it explicitly limit queue capacity. Currently, the reader logs the messages it reads and, possibly, sends an email to a designated support account. See RabbitMQ Dead Letter Exchanges for more information.
Runtime Architecture¶
In previous sections we described the components of the new Jobs service; in this section we describe how those components can be arranged in a runtime environment.
The Aloe Jobs service is essentially a drop-in replacement for the Tapis Jobs service: the new service runs in any existing Tapis installation minus its legacy Jobs service. The existing services, including the Notifications service with its own persistent backend, continue to be configured and managed as before. The configuration of authentication servers, proxies and load balancers also remains unchanged for existing Tapis services.
The new Jobs service web applications, workers and readers are delivered as Docker images, so these components can be easily deployed and redeployed on different hosts at runtime. All deployments, however, observe the following constraints:
- The web application URLs are the only external facing interface and, therefore, should be stable.
- Web applications, workers and recovery readers must have network access to the site’s MySQL and RabbitMQ management systems.
- Alternate and dead letter readers must have network access to the site’s RabbitMQ management system.
By splitting the single legacy web application between two new web applications (Application Layer), we introduce the need for URL-specific routing within the Jobs service. One way to achieve this routing is to define URL rewrite rules in a proxy such Apache httpd or nginx. Below is an example of Apache rewrite rules that route Job service URLs to their proper web application.
# All GET requests for jobs service should go to legacy-jobs service.
RewriteCond %{REQUEST_URI} ^/jobs
RewriteCond %{REQUEST_METHOD} =GET
RewriteRule ^/jobs(.*)$ http://proxy.host:7999/legacy-jobs$1 [P]
# POST/PUT/DELETE requests for job permission should go to legacy-jobs /pems end-point.
RewriteCond %{REQUEST_URI} ^/jobs/.*/pems
RewriteCond %{REQUEST_METHOD} !=GET
RewriteRule ^/jobs(.*)$ http://proxy.host:7999/legacy-jobs$1 [P]
# All other none-GET requests for the jobs service should go to aloe-jobs service.
RewriteCond %{REQUEST_URI} ^/jobs
RewriteCond %{REQUEST_URI} !^/jobs/.*/pems
RewriteCond %{REQUEST_METHOD} !=GET
RewriteRule ^/jobs(.*)$ http://proxy.host:8081/jobs/v2$1 [P]
For capacity planning and management, we recommend putting the workers and readers on different hosts than the web applications. Worker and reader daemons for multiple tenants can share the same host. Since these daemons communicate only through the persistence layer, they can be moved between hosts without any reconfiguration as long as network connectivity is maintained.
The number and placement of workers is largely a matter of administrative convenience, expected load and resource availability. Review the Scalability section for a discussion of vertical and horizontal scaling options.
We recommend installing MySQL and RabbitMQ on their own virtual or physical hosts with reliable storage, automated backups, and sufficient network, memory and processing resources. Whereas application layer components can be easily moved between hosts, the persistence layer components are not expected to change addresses often if at all. All tenants depend on a stable persistence layer, so there’s little benefit in containerizing these components; we recommend native installation of MySQL and RabbitMQ in production environments.